Overview of Microsoft DP-100 Exam
The Microsoft DP-100 exam, officially titled "Designing and Implementing a Data Science Solution on Azure," is a certification test designed for data scientists who work with Microsoft Azure. The exam assesses a candidate’s ability to design and implement machine learning models, manage data pipelines, and optimize AI solutions using Azure Machine Learning (Azure ML).
Microsoft DP-100 is a critical certification for professionals aiming to establish expertise in the AI and data science field, particularly within the Microsoft ecosystem. It validates skills in working with datasets, selecting appropriate machine learning models, and deploying solutions effectively. Earning the DP-100 certification demonstrates proficiency in leveraging Azure's robust AI and ML tools to build scalable data-driven solutions.
Understanding Data Types and Their Impact on Model Selection
In data science, understanding different data types is crucial as they directly impact model selection and performance. Data types determine the type of analysis that can be performed, the preprocessing required, and the suitability of machine learning algorithms. The primary data types include:
1. Numerical Data
- Continuous Data: Values that can take any number within a range (e.g., temperature, weight, height).
- Discrete Data: Values that are countable and have finite possibilities (e.g., number of customers, product quantity).
2. Categorical Data
- Nominal Data: Categories without a specific order (e.g., gender, color, city name).
- Ordinal Data: Categories with a meaningful order (e.g., satisfaction ratings, education levels).
3. Text Data
- Includes words, sentences, and structured text. Common in NLP applications.
4. Time-Series Data
- Data recorded over time (e.g., stock prices, weather reports).
5. Image and Video Data
- Used in computer vision tasks and deep learning applications.
Understanding these data types helps in choosing appropriate preprocessing techniques and machine learning models for optimal results.
Common Machine Learning Models and Their Use Cases
Choosing the right machine learning model depends on the dataset characteristics and the problem to be solved. Here are some commonly used models and their applications:
1. Linear Regression
- Use Case: Predicting continuous values, such as housing prices or sales revenue.
- Best For: When relationships between variables are linear.
2. Logistic Regression
- Use Case: Binary classification tasks like spam detection or fraud detection.
- Best For: When the target variable is categorical (e.g., 0 or 1, yes or no).
3. Decision Trees
- Use Case: Customer segmentation, credit risk analysis.
- Best For: Handling both numerical and categorical data with complex decision-making.
4. Random Forest
- Use Case: Disease prediction, recommendation systems.
- Best For: Reducing overfitting seen in decision trees.
5. Support Vector Machines (SVM)
- Use Case: Text classification, image recognition.
- Best For: High-dimensional data and small datasets.
6. Neural Networks & Deep Learning
- Use Case: Speech recognition, autonomous driving, facial recognition.
- Best For: Complex patterns and unstructured data (text, images, videos).
7. Clustering Algorithms (K-Means, DBSCAN, Hierarchical Clustering)
- Use Case: Customer segmentation, anomaly detection.
- Best For: Grouping similar data points together.
8. Reinforcement Learning
- Use Case: Game playing AI, robotics, stock trading strategies.
- Best For: Decision-making problems requiring sequential actions.
Steps to Determine the Best Model for a Given Dataset
Choosing the right machine learning model is a systematic process that involves several key steps:
1. Define the Problem Statement
- Determine if the task is classification, regression, clustering, or reinforcement learning.
- Example: Predicting customer churn (classification) vs. forecasting sales (regression).
2. Understand the Data
- Perform exploratory data analysis (EDA).
- Identify missing values, outliers, and relationships between features.
- Visualize data using histograms, scatter plots, and correlation matrices.
3. Preprocess the Data
- Handle missing values (imputation, deletion).
- Normalize/standardize numerical features.
- Encode categorical variables (one-hot encoding, label encoding).
- Perform feature selection and extraction.
4. Split the Dataset
- Divide data into training, validation, and testing sets.
- Common split ratios: 80-10-10 or 70-20-10.
5. Select Suitable Models
- Choose models based on data characteristics and problem type.
- Example: Use logistic regression for binary classification and random forest for complex decision-making.
6. Train and Evaluate Models
- Train models on the training set and validate performance using validation data.
- Use metrics such as accuracy, precision, recall, F1-score (for classification) and RMSE, R² (for regression).
7. Tune Hyperparameters
- Optimize model parameters using Grid Search, Random Search, or Bayesian Optimization.
8. Compare Model Performance
- Compare multiple models and select the best-performing one based on evaluation metrics.
9. Deploy the Model
- Deploy the model using Azure ML services.
- Monitor performance and retrain as necessary.
10. Continuous Improvement
- Regularly update the model with new data.
- Implement model retraining pipelines.
Conclusion
The Microsoft DP-100 exam is a crucial certification for data scientists who want to validate their expertise in Azure-based machine learning solutions. Understanding data types is fundamental in selecting the best machine learning models. From regression and classification to deep learning and clustering, each model has specific use cases that align with different business problems.
The process of selecting the right model involves understanding the problem, exploring data, preprocessing, training, evaluating, and optimizing models. By mastering these concepts, professionals can efficiently design and implement machine learning solutions in Microsoft Azure.
DumpsBoss provides high-quality study materials, including DP-100 practice tests and dumps, to help candidates prepare effectively for the exam. With the right resources and structured learning, you can achieve success in your Microsoft DP-100 certification journey.
Special Discount: Offer Valid For Limited Time “DP-100 Exam” Order Now!
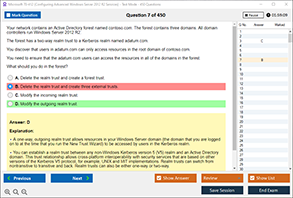
Sample Questions for Microsoft DP-100 Dumps
Actual exam question from Microsoft DP-100 Exam.
Which kind of model best describes this set of data?
A. Linear Regression
B. Decision Tree
C. Neural Network
D. Clustering